Utilisation¶
L’Optimizer fournit différentes techniques d’optimisation, telles qu’une approche séquentielle semi-automatique, des simulations de Monte-Carlo et une technique d’optimisation globale utilisant des algorithmes génétiques. L’établissement d’une relation statistique entre les prédicteurs et les prédictants est gourmand en ressources informatiques car il nécessite de nombreuses évaluations sur plusieurs décennies.
La calibration des MAs est généralement effectuée dans un cadre de pronostic parfait (perfect prognosis framework). Le pronostic parfait utilise des données observées ou réanalysées pour calibrer la relation entre les prédicteurs et les prédictants. En conséquence, le pronostic parfait produit des relations qui sont aussi proches que possible des liens naturels entre les prédicteurs et les prédictants. Cependant, il n’existe pas de modèles parfaits, et même les données de réanalyse peuvent contenir des biais qui ne peuvent être ignorés. Ainsi, les prédicteurs considérés doivent être aussi robustes que possible, c’est-à-dire qu’ils doivent avoir une dépendance minimale vis-à-vis du modèle.
Une relation statistique est établie par essais et erreurs en calculant une prévision pour chaque jour d’une période de calibration. Un certain nombre de jours proches de la date cible sont exclus afin de ne prendre en compte que les jours candidats indépendants. Il est très important de valider les paramètres des MA sur une période de validation indépendante afin d’éviter une sur-paramétrisation et de s’assurer que la relation statistique est valable pour une autre période. Afin de tenir compte des changements climatiques et de l’évolution des techniques de mesure, il est recommandé d’utiliser une période de validation non continue, répartie sur l’ensemble des archives (par exemple, 1 année sur 5). Les utilisateurs d’AtmoSwing peuvent ainsi spécifier une liste d’années à mettre à part pour la validation qui sont retirées des situations candidates possibles. À la fin de l’optimisation, le score de validation est traité automatiquement. Les différents scores de vérification disponibles sont détaillés ici.
Exigences¶
L’Optimizer a besoin :
Méthodes de calibration¶
L’Optimizer propose différentes approches, énumérées ci-dessous.
Approches d’évaluation uniquement¶
Ces méthodes ne cherchent pas à améliorer les paramètres des MAs. Elles permettent certaines évaluations à l’aide des paramètres fournis. Les différents scores de vérification disponibles sont détaillés ici.
Évaluation unique : Cette approche traite la MA comme décrit dans le fichier de paramètres fourni et évalue le score défini.
Évaluation de tous les scores : Identique au précédent, mais évalue tous les scores disponibles.
Uniquement les valeurs prédictives : Ne calcule pas de score de vérification, mais calcule la MA et enregistre les valeurs analogues dans un fichier.
Uniquement les dates analogues (et les critères) : Ne calcule pas de score de vérification et n’attribue pas de valeurs du prédictant aux dates analogues. Enregistre un fichier avec uniquement les dates analogues identifiées par la MA définie.
Basé sur la calibration classique¶
La calibration classique est détaillé ici.
Calibration classique : La calibration classique
Calibration classique+ : Une variante de la calibration classique avec quelques améliorations.
Exploration de variables Classique+ : Utilisation de la calibration classique+ pour explorer systématiquement une liste de variables / niveaux / heures.
Optimisation globale¶
Algorithmes génétiques : L’optimisation utilisant des algorithmes génétiques.
Exploration aléatoire de l’espace des paramètres¶
Simulations de Monte-Carlo : Exploration de l’espace des paramètres à l’aide de simulations de Monte-Carlo. Ces simulations se sont révélées limitées en termes de capacité à trouver des jeux de paramètres raisonnables pour des MA même modérément complexes (1 à 2 niveaux d’analogie avec quelques prédicteurs).
Sorties¶
L’Optimizer produit différents fichiers :
Un fichier texte avec le meilleur jeu de paramètres résultant et le score de vérification ([…]best_parameters.txt).
Un fichier texte contenant tous les paramètres évalués et leur score de vérification correspondant ([…]tested_parameters.txt).
Un fichier xml avec les meilleurs paramètres (à utiliser par AtmoSwing Forecaster/Downscaler ; […]best_parameters.xml).
Un fichier NetCDF contenant les dates analogues (AnalogDates[…].nc) pour les périodes de calibration et de validation.
Un fichier NetCDF contenant les valeurs analogues (AnalogValues[…].nc) pour les périodes de calibration et de validation.
Un fichier NetCDF contenant les scores de vérification (Scores[…].nc) pour les périodes de calibration et de validation.
Interface utilisateur graphique¶
L’interface principale de l’Optimizer est la suivante.
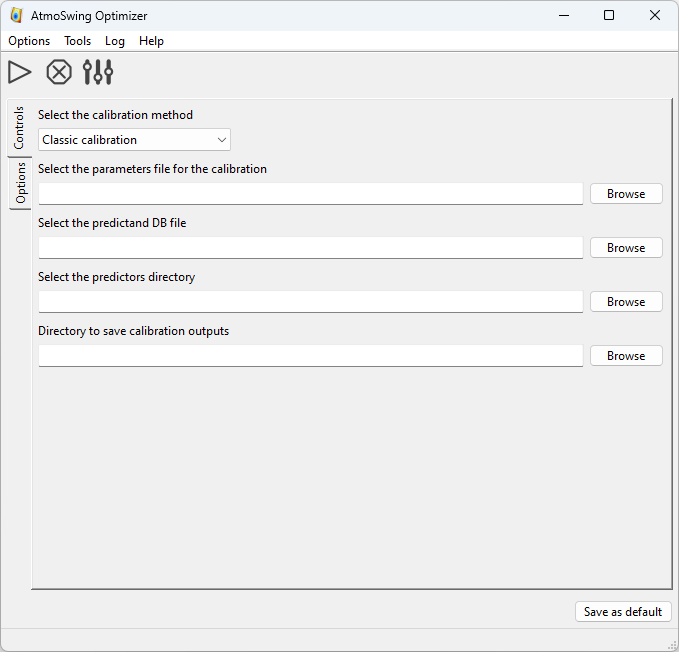
La barre d’outils permet d’effectuer les actions suivantes :
 Démarrer l’optimisation.
Démarrer l’optimisation. Arrêter les calculs en cours.
Arrêter les calculs en cours. Définir les préférences.
Définir les préférences.
Éléments nécessaires :
Sélectionnez une des méthodes de calibration
Le répertoire contenant les prédicteurs pour la période d’archive
Le répertoire pour sauvegarder les résultats
Toutes les options de la méthode de calibration sélectionnée (dans l’onglet Options ; voir ci-dessous)
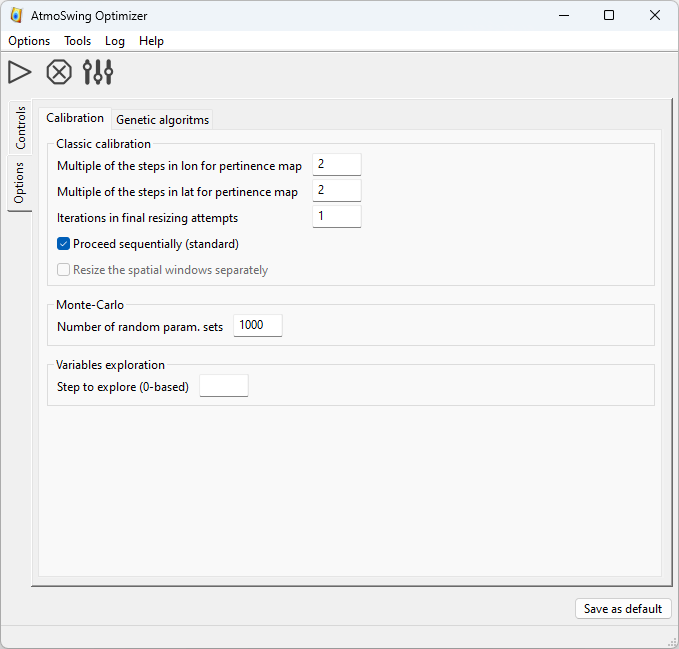
Un onglet permet de définir les options de la calibration classique, de l’exploration des variables et des simulations de Monte-Carlo. Les détails des options sont donnés ici.
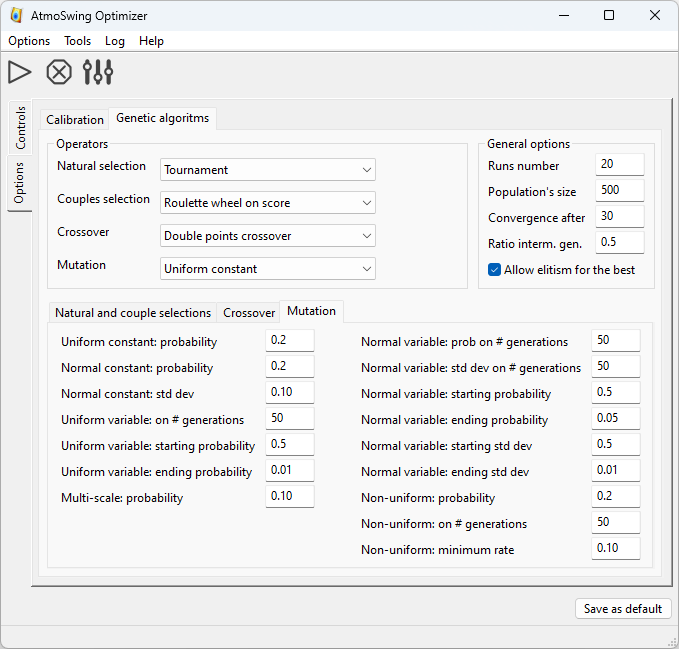
L’autre onglet fournit de nombreuses options pour les algorithmes génétiques. Le détail des options est donné sur la page des algorithmes génétiques.
Interface en ligne de commande¶
L’Optimizer dispose également d’une interface en ligne de commande, qui est le mode d’utilisation préférable. Les options sont les suivantes :
- -h, --help
Afficher l’aide des options en ligne de commande
- -v, --version
Afficher la version du logiciel
- -s, --silent
Mode silencieux
- -l, --local
Travail dans le répertoire local
- -n, --threads-nb=<n>
Nombre de threads à utiliser
- -g, --gpus-nb=<n>
Nombre de gpus à utiliser
- -r, --run-number=<nb>
Un numéro pour le run
- -f, --file-parameters=<file>
Fichier contenant les paramètres
- --predictand-db=<file>
La base de données des prédictants
- --station-id=<id>
L’ID de la station du prédictant
- --dir-predictors=<dir>
Le répertoire des prédicteurs
- --skip-valid
Sauter le calcul de validation
- --no-duplicate-dates
Ne pas permettre de garder plusieurs fois les mêmes dates analogues (par exemple pour les ensembles)
- --dump-predictor-data
Décharge les données du prédicteur dans des fichiers binaires pour réduire l’utilisation de la RAM
- --load-from-dumped-data
Chargement des données déchargées (binaires) du prédicteur dans la RAM (chargement plus rapide)
- --replace-nans
Option pour remplacer les NaN par -9999 (traitement plus rapide)
- --skip-nans-check
Ne pas vérifier les NaN (traitement plus rapide)
- --calibration-method=<method>
Choix de la méthode de calibration :
single: évaluation uniqueclassic: calibration classiqueclassicp: calibration classique+varexplocp: exploration des variables avec classique+montecarlo: Simulations de Monte Carloga: algorithmes génétiquesevalscores: évalue tous les scoresonlyvalues: calcule uniquement les valeurs analoguesonlydates: calcule uniquement les dates analogues
- --cp-resizing-iteration=<int>
Classique+ : itération de redimensionnement
- --cp-lat-step=<step>
Classique+ : pas (résolution) en latitudes pour la carte de pertinence
- --cp-lon-step=<step>
Classique+ : pas (résolution) en longitudes pour la carte de pertinence
- --cp-proceed-sequentially
Classique+ : procéder de manière séquentielle
- --ve-step=<step_nb>
Exploration des variables : étape à traiter
- --mc-runs-nb=<runs_nb>
Monte Carlo : nombre de simulations
- --ga-xxxxx=<value>
Toutes les options des GAs sont décrites sur la page des algorithms génétiques
- --log-level=<n>
Définir le niveau du journal (0 : minimum, 1 : erreurs, 2 : avertissements (par défaut), 3 : verbeux)